¡Muy buenas a todos/as y bienvenidos/as otra semana más!
Hoy, os explico el paso a paso de cómo hemos montado nuestro propio asistente con IA usando una Orange Pi con ARMBIAN y Tiny llama, un LLM que no necesita GPU para poder ejecutarse y que además consume MUY POCOS recursos a nivel de hardware.
Os dejo además el video dónde explicamos las bondades de la IA y dónde enseñamos el funcionamiento final de nuestro asistente:
Es por eso, que una Orange Pi será suficiente para poder tener nuestro propio asistente con la opción de poder entrenarlo a nuestro gusto en el futuro.
Pues bien, vamos con el paso a paso, lo primero que vamos a necesitar va a ser tener nuestra Orange Pi preparada y lista con ARMBIAN, un sistema operativo MUY ligero que podemos descargar y quemar en una tarjeta SD para colocarla en nuestra Orange Pi.
Una vez arrancada nuestra Orange Pi, empezamos abriendo una terminal para teclear los siguientes comandos:
0. Preparación del entorno
Antes de nada y para preparar el entorno, actualizamos la lista de paquetes disponibles desde los repositorios configurados en nuestro sistema, instalamos git y herramientas básicas de compilación en C/C++:
1. Clonar el repositorio con el código fuente
Este comando descarga el proyecto llama.cpp desde GitHub y crea una carpeta local con el mismo nombre que contiene todo el código.
2. Entrar en el directorio del proyecto
Con este comando accedemos a la carpeta descargada (llama.cpp) para poder trabajar dentro de ella.
3. Actualizar la lista de paquetes
Antes de instalar dependencias, es recomendable actualizar la base de datos de paquetes del sistema para asegurarse de obtener las versiones más recientes disponibles.
4. Instalar CMake
Se instala CMake, la herramienta de construcción multiplataforma necesaria para generar los archivos de compilación de llama.cpp.
5. Acceder al directorio de compilación
Entramos a la carpeta build/, destinada a organizar los archivos generados durante la compilación sin ensuciar el código fuente principal.
6. Instalar librerías de desarrollo para cURL
Se instala libcurl4-openssl-dev, una librería que permite al programa realizar peticiones HTTP/HTTPS (muy útil, por ejemplo, para integrarse con Hugging Face).
7. Generar los archivos de compilación
Ejecutamos CMake para que analice el proyecto y cree los ficheros necesarios para compilar llama.cpp.
8. Compilar el proyecto
Ahora se construye el programa: a partir de los archivos fuente de llama.cpp se generan los ejecutables dentro de la carpeta bin/.
9. Volver al directorio principal
Se regresa al directorio raíz del proyecto (llama.cpp) para seguir trabajando con las carpetas principales, en este caso la de modelos.
10. Moverse al directorio de modelos
Entramos en la carpeta models/, que es donde guardaremos los ficheros del modelo Tiny Llama que vamos a descargar.
11. Descargar el modelo Tiny Llama desde Hugging Face
Con wget descargamos el modelo en formato GGUF, utilizando un token de autenticación «TOKEN» para validar el acceso a Hugging Face.
El archivo descargado se guardará localmente como tinyllama.gguf.
Pero antes de nada… hablemos de CÓMO OBTENER NUESTRO TOKEN y de POR QUÉ lo necesitamos. Y es que, el paso de obtener un token de Hugging Face no es realmente para que el modelo «funcione», sino para poder acceder a los ficheros del modelo alojados en Hugging Face Hub.
Muchos modelos (incluido Tiny Llama) están publicados en el Hugging Face Hub, que funciona como un «GitHub para modelos de IA». De hecho, algunos modelos son completamente públicos, pero otros requieren aceptar términos de uso (por ejemplo, licencias o avisos de uso responsable). De manera que, el TOKEN es la forma de demostrar que hemos aceptado esos términos y que tenemos permiso para descargarlos. Así pues, el TOKEN permite que identifiquen a los usuarios, apliquen límites de uso justos y se eviten abusos.
Si NO quisiéramos usar Hugging Face para descargarnos en modelo de IA y si ya lo tuviéramos descargado completamente y lo guardamos en nuestra Orange Pi, podríamos cargarlo directamente sin necesidad de acceder a Hugging Face ni usar ningún TOKEN.
No obstante, y para hacer las cosas a mi parecer mas sencillas, la forma más fácil y oficial de obtener Tiny Llama seria descargándolo desde Hugging Face con el TOKEN.
Así que… antes de realizar la descarga… tenemos que ir a Hugging Face y crearnos una cuenta, para dirigirnos al apartado «Access Tokens» y el botón «+ Create New Token», para poder obtener nuestro TOKEN:
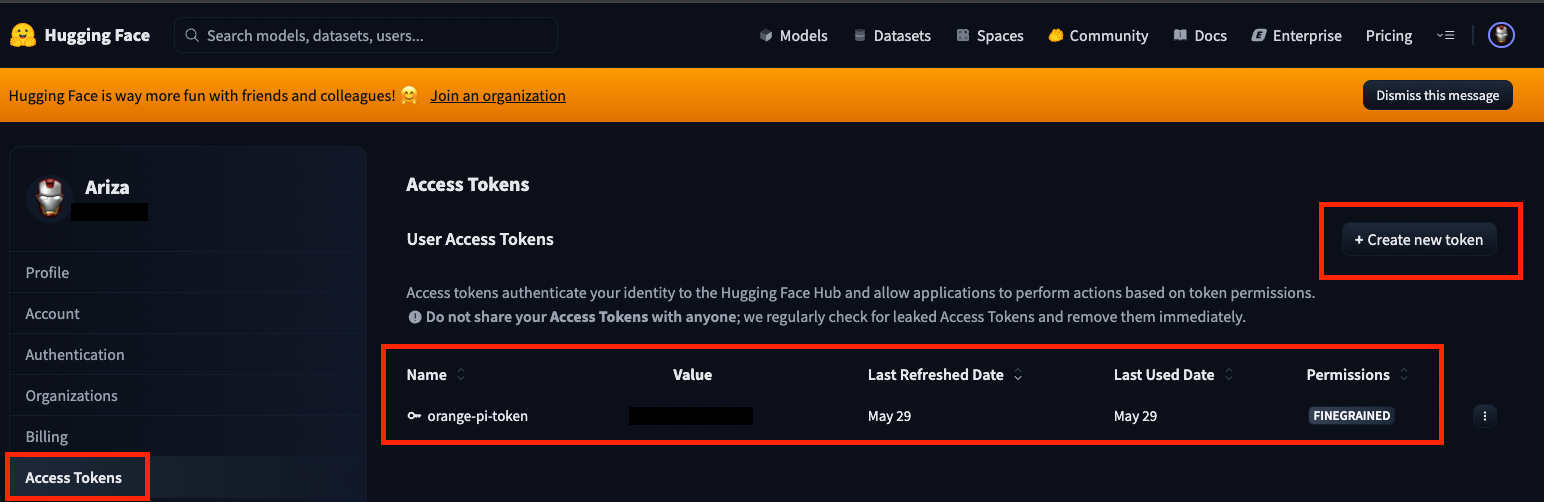
MUY IMPORTANTE: Cuando estemos creando cualquier TOKEN en Hugging Face y lo generemos, nos aparecerá siempre el siguiente mensaje avisándonos de que AHORA es el momento de copiarlo y GUARDARLO ya que no vamos a poder volver a ver su valor en el futuro:
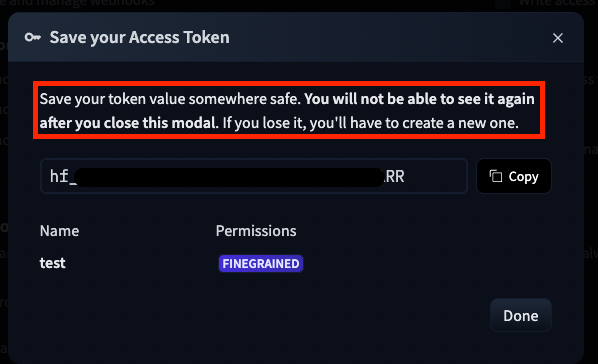
Una vez, generado nuestro TOKEN y guardado su valor, ya lo podemos usar en nuestro entorno.
12. Ejecutar Tiny Llama con un prompt de prueba
Finalmente, lanzamos el binario llama-cli, indicando el modelo a usar (tinyllama.gguf) y el mensaje inicial o prompt: «Hola, ¿quién eres?»
Y aquí es cuando el modelo nos responde por primera vez:
✅ Con estos pasos, tu Orange Pi queda lista para ejecutar Tiny Llama de manera local, sin depender de servicios externos más allá de la descarga inicial del modelo.